

刚刚落下帷幕的第六届全国社会媒体处理大会(SMP CUP 2017),由中国中文信息学会社会媒体处理专委会主办、CSDN协办并赞助。此次用户画像技术评测参赛选手以研究生为主,共有来自全球的200多家单位的757名选手,332支参赛队伍参赛。我校网络空间安全学院在李斌阳副教授的指导下,由大三学生陆俊如、陈乐、孟孔明、王凤仪、向君、周凯敏、董镇远、单佳炜、廉令晨、姜宁组成的ELP团队在赛事中脱颖而出,最终斩获了第六名的佳绩。

此次,CSDN技术论坛的用户画像问题共包含三个不同维度的子任务,分别为:用户内容关键词生成,用户兴趣标注以及用户成长值预测。
任务1
用户内容主题词生成
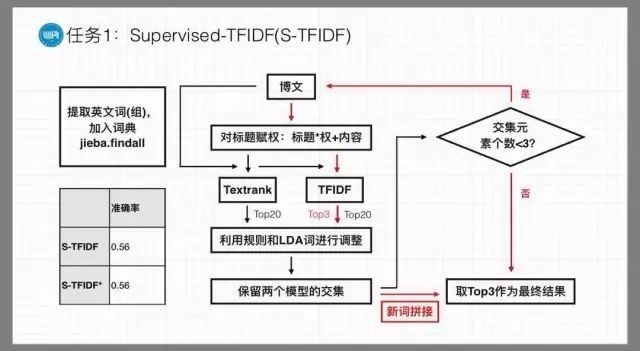
任务为给定若干用户文档(博客或帖子),参赛者需要为每一篇文章生成3个最合适的主题词,且生成的主题词必须出现在文档中。由于内容主题词是一个相对开放且主观的概念,候选词的精准选择难度较大,所以如何在众多候选词中生成最合适且与目标词相符的主题词,是该任务的关键点。
我校ELP团队设计了自定义词表和自适应规则的办法来解决这一任务。在jieba自带词典的基础上,针对文档主题集中在计算机科学、人工智能、自然语言处理等领域的特性,从搜狗细胞词库中搜索了相关词表进行扩充。此外,构建了基于本数据集的LDA关键词词典、IDF词典及训练集关键词词典。同时,采用自定义规则,针对词长、英文、标题对关键词序列的初始权重进行调整。
预处理后的文本分别经由Textrank与TFIDF处理,经上述规则调整后,获取得分最高的20个关键词,保留交集。若交集元素不足,则采用TFIDF模型进行新词拼接。

任务2
用户兴趣标注
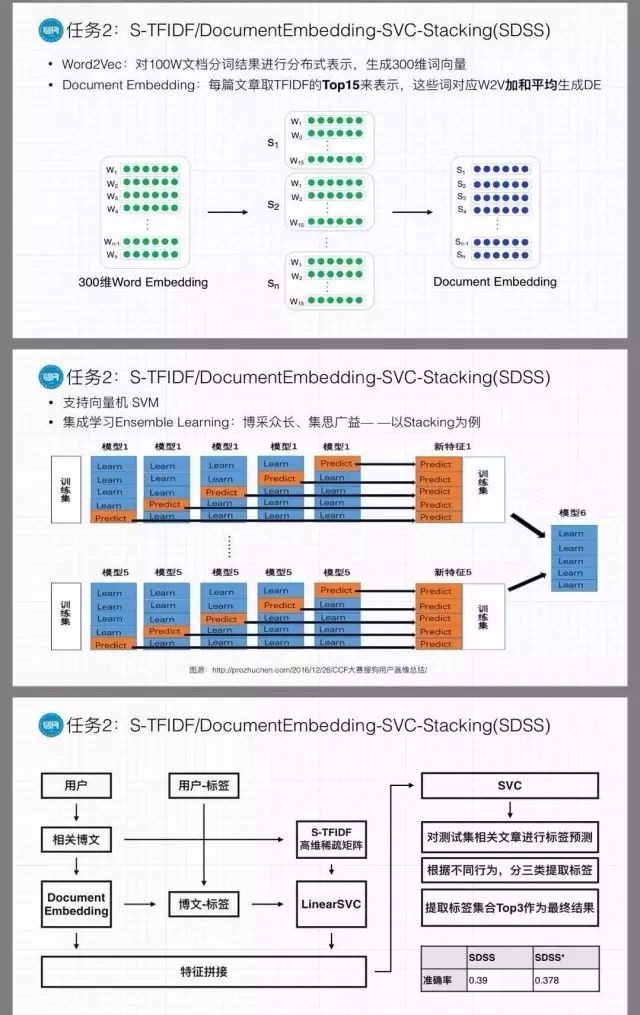
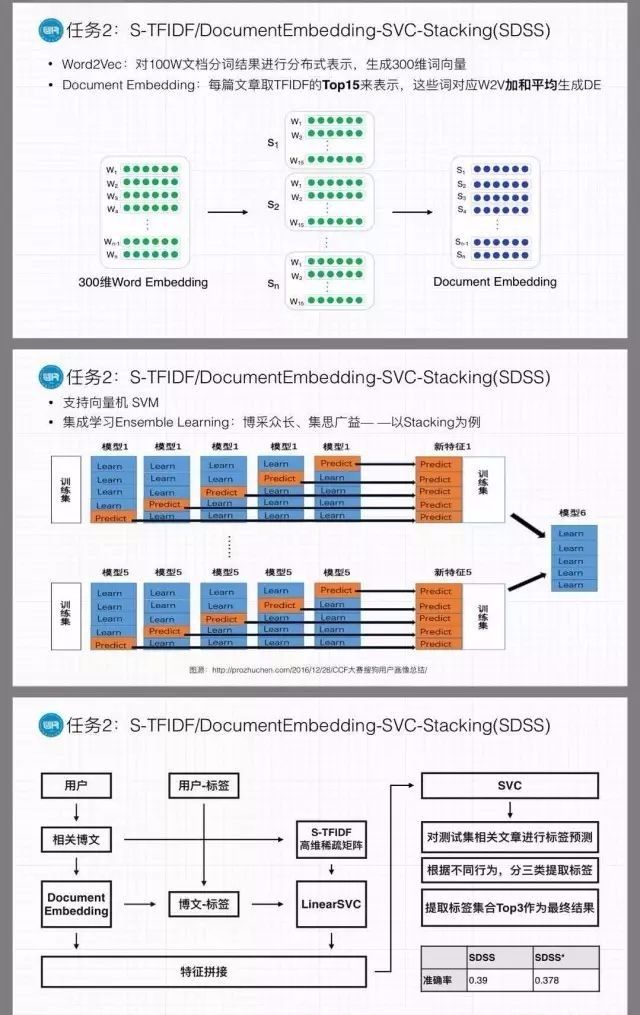
任务为给定若干用户的文档信息(博客或帖子)和行为数据(浏览、评论、收藏、转发、点赞/踩、关注、私信等),参赛者需要为每一个用户标注3个最合适的兴趣方向。标签空间由CSDN给定,共42维。题目给出的训练样本数量非常少,模型过拟合的概率较大,因此对用户标注兴趣方向对团队来说是一项很大的挑战。
我校ELP团队对一百万篇文档分词结果进行分布式表示,生成300维词向量,通过每篇文档Top15关键词对应的词向量为其生成Document Embedding。同时利用任务1的S-TFIDF模型生成最相关主题词与高维特征值,置入SVM模型中进行分类预测。之后,将结果进行特征拼接,调用Stacking框架进行集成学习,进一步提升预测效果并根据不同行为分类为用户返回兴趣标签。

任务3
用户成长值预测
任务为给定若干用户在一段时间内(至少一年)的文档信息(博客或帖子)和行为数据(浏览、评论、收藏、转发、点赞/踩、关注、私信等),参赛者需要预测每一个用户在未来一段时间内(半年或1年)的成长值。在CSDN这样的开放系统下,预测用户未来的行为以及成长值难度较大,而标签数据也较少,这使得该任务非常具有挑战性。
我校ELP团队首先在月时间级别进行了用户7种行为的统计,再以此为基础,抽取均值、Log和增长率等特征并进行拼接。根据任务特性,我队在任务2的基础上使用了被动感知模型与梯度上升模型作为下层弱学习器并鉴于模型预测的随机性设计了多轮训练情况下的阈值判定条件。

ELP团队任务1、任务2、任务3的得分分别为0.563、0.378、0.751。我校团队坚持不懈,用汗水和才智铸就了辉煌的战果。
让我们对ELP团队所取得的优异成绩表示祝贺!
今天付出,明天收获,全力以赴,永不言退,咱们是最好的团队,最好的网安!

文稿:秘书处 刘川









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}